12 Days of OpenAI Shipmass
Some incredible new AI tools have just been released and announced over the past couple of weeks


This year OpenAI decided to finish the year with a slew of product announcements, which were spread out over the twelve days of “shipmass”. The most impressive product launches happened on the first few days, including the launch of full o1 model on day one, and public access to Sora on day 3. However, the most staggeringly impressive announcement came on day 12, when OpenAI announced o3, their upcoming reasoning model and a successor to 1. (Presumably o2 moniker was copyrighted.)
I have been using the pro version of o1 for a couple of weeks, and have been blown away by its capabilities, be it solving complex chess puzzles consistently, explaining or writing code, creating long detailed (and accurate!) research reports, and a whole bunch of other impressive tasks. However, it seems like o1 is a downright dummy compared to o3. OpenAI shared some results from several highly competitive benchmarks, mostly focused on advanced math, scientific reasoning, and coding. Some of these benchmarks are extremely challenging, and on them o3 showed an almost superhuman power. Here are some of the results:
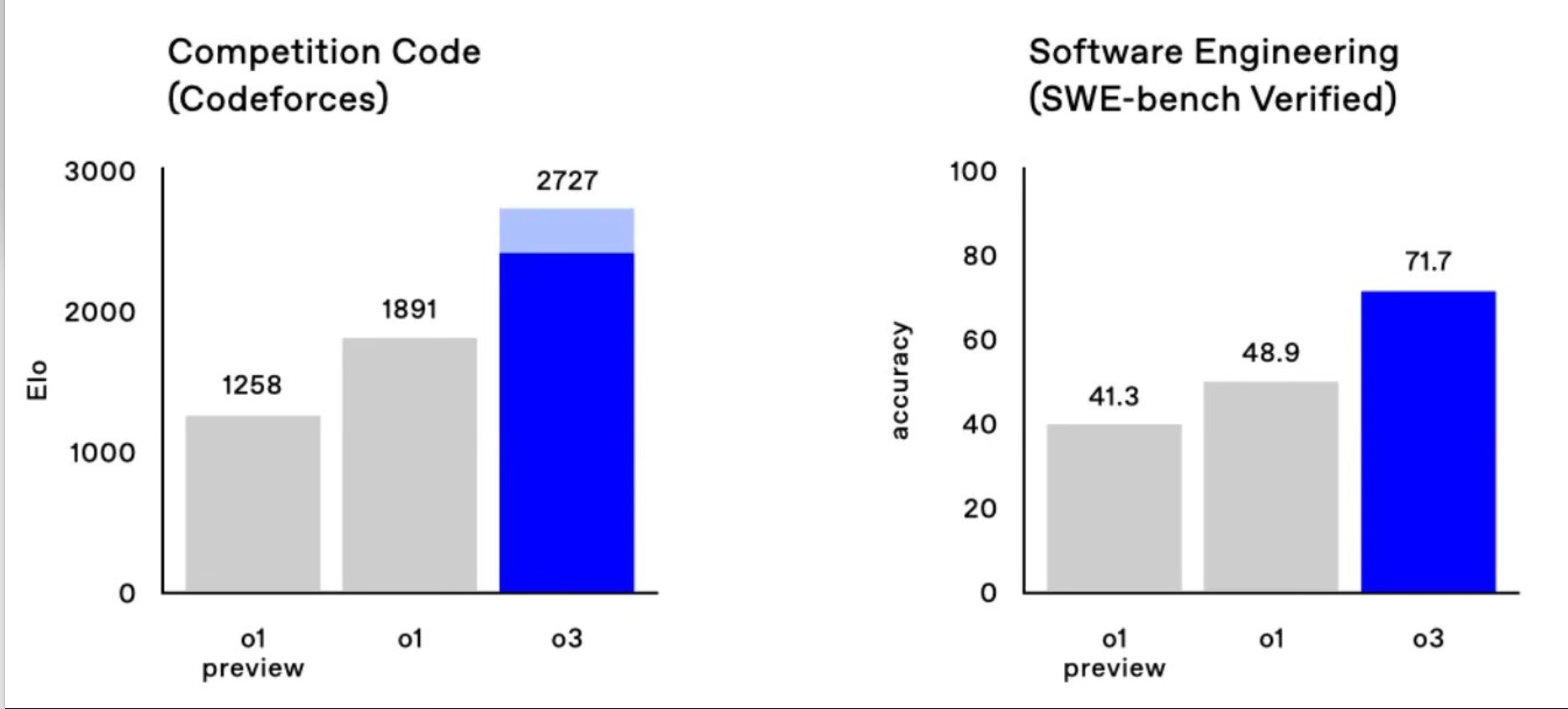
The Elo of 2727 on Codeforces, for instance, means that o3 is better than all but about 175 humans! The improvements over SWE-bench are equally impressive. Just a few months ago the best LLM would only be able to operate in a single percentage accuracy!
On Frontier math problems o3 improved from 2% SOTA accuracy to well over 25%. these are ridiculously hard math problems, with the easier ones being on the level of math olympiads, and the harder ones being at the level of PhD researcher projects.

The most astonishing, to me at least, has been o3’s performance at the ARC-AGI prize. It has blown past all the previous AI systems, and o1 in particular, and with extra compute budget it was able to achieve 88% accuracy. ARC problems are extremely hard cognitively loaded problems, that thus far have been emblematic of what qualitatively distinguished human intelligence from the machine intelligence. For instance, human performance on ARC problems is about 85% accuracy.
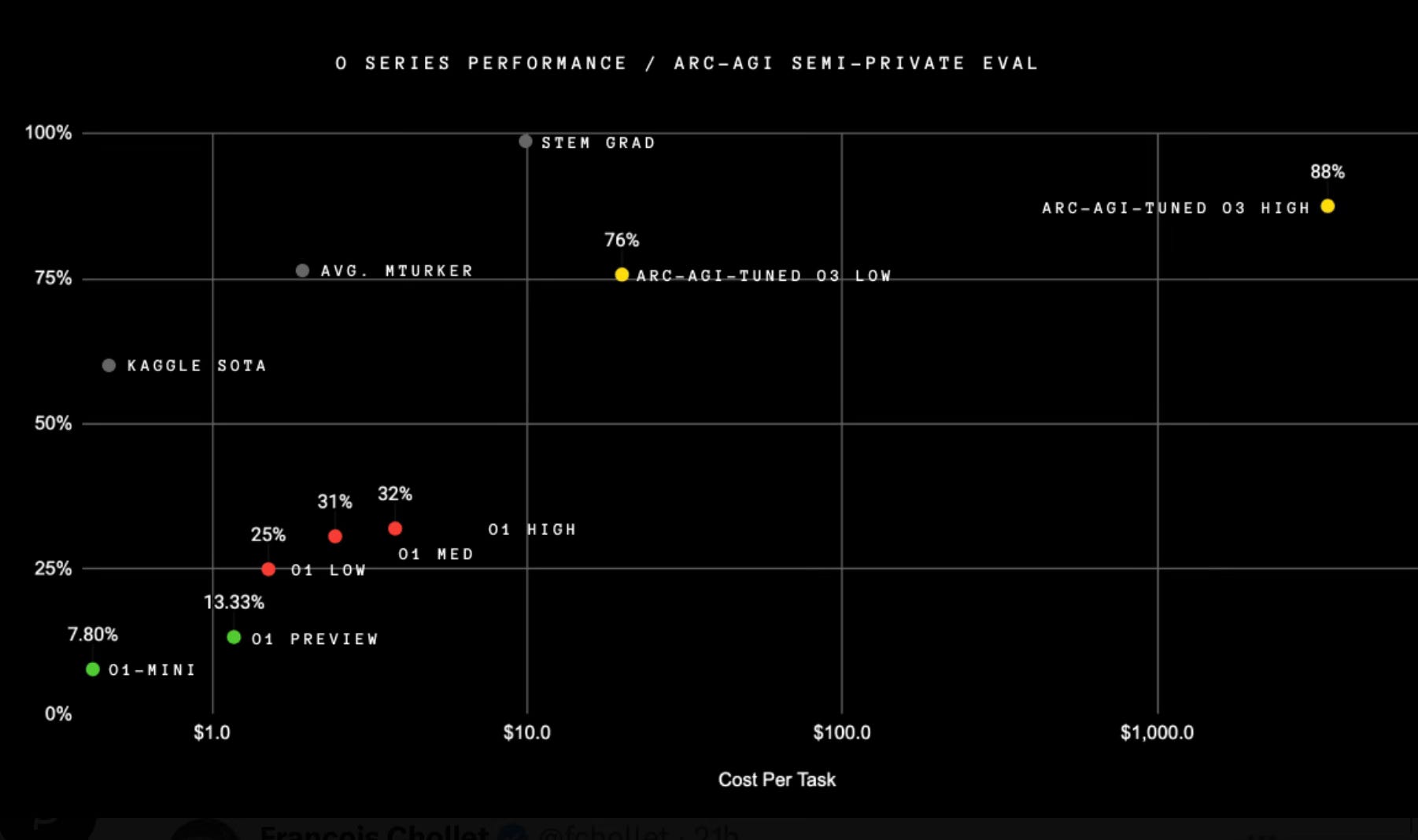
This is all pretty epochal, with many commentators arguing that the true AGI has been achieved. It is possible to quibble about whether this is true or not, but the fact remains that in the right hands o3 can be an extremely powerful tool. Fortunately or unfortunately, o3 is still not available to the public. The OpanAI safety team is currently red-teaming and testing it. They expect to release o3-mini in the late January. This model will be slightly better than o1, with dramatically more affordable price per compute value. And the full o3 should become available not too long after that. All in all, this is an incredibly exciting developed for everyone who wants to use AI in their work. I for one can’t wait to get access to all of it!
Very cool post! Installed the substack app for reading this post, lol. Hope to see some tech report about o3. O1 and o1-mini are quite limited